Review your OpenAPI spec
liblab can convert any OpenAPI 2.0 (Swagger), 3.0 or 3.1 compliant spec into an SDK in multiple languages. To get the best result, your spec needs to contain certain features, or have certain fields filled in (or set in the liblab.config.json file).
Here are some tips to review your spec before SDK generation.
Validate your YAML or JSON
OpenAPI specs are defined using YAML or JSON, and have to follow a strict schema that is defined by OpenAPI. Before creating an SDK you should validate your YAML or JSON to ensure it is both structurally correct, and that it conforms to the OpenAPI specification.
There are a number of tools that can do this validation, and we recommend ones that are built in to, or are extensions for VS Code.
-
Validate your JSON - If your schema is defined as JSON then the built in validation in VS Code will let you know if your JSON has any structural errors, such as values not in quotes, or mismatched braces. VS Code can format your JSON to make it easier to read to help with reviewing your spec.

In the example above, the
titleis not in quotes, and so shows an error. -
Validate your YAML - To validate your YAML, install the YAML by Red Hat VS Code extension. This will verify things like indentation.
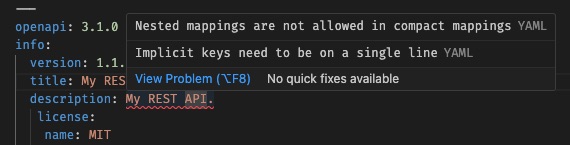
In the example above, the
licensesection is incorrectly indented, leading to an error on the line above.
Once you have validated your spec for structural correctness, the next step is to validate the content.
Validate the spec file content
To ensure you get the best SDK possible, here are some features you need to check.
Operation Ids
APIs have endpoints that can be called using one or more verbs, for example GET and POST. In your OpenAPI spec these are defined as paths with operations, with the endpoint mapping to a path, and the verbs mapping to an operation. For your spec to be valid, each combination of path and verb must be unique - you can't have 2 get operations on the books path for example.
Here's an example of part of a spec with 2 get operations for different paths, a GET operation on the book endpoint to return all books, and a GET operation on the book/{id} endpoint to retrieve a specific book by its ID:
paths:
/book:
get:
...
/book/{id}:
get:
...
When generating SDKs, there's no way from this for liblab to pick perfect names for the SDK methods that will be created, so it will make a best guess. In this case, you would get the following:
def get(self) -> PagedBooksModel:
...
def get_by_id(self, id: str) -> BookModel:
...
This might be perfect for your needs, but you may want to specify the names for these methods. This can be done by setting the operationId field on the path:
paths:
/book:
get:
operationId: listBooks
...
/book/{id}:
get:
operationId: getBook
...
This gives a nicer SDK:
def list_books(self) -> PagedBooksModel:
...
def get_book(self, id: str) -> BookModel:
...
liblab is smart enough to adjust the casing to suit the standards for the SDK language. For example an operationId of listBooks will be list_books in Python, and listBooks in TypeScript.
You should always provide operation ids to help your SDK be developer friendly. For example, having a POST operation on the book endpoint without an operation id will lead to a method called create, which is not a great developer experience for an SDK. It will also have a response called CreateResponse. Ideally this method would be named something like CreateBook, which can be set by providing an operation id of createBook. The generated SDK will convert this to the relevant case for the language, so create_book for Python, and createBook for TypeScript.
liblab will also try to avoid name clashes which can happen if you have multiple endpoints with the same tag and the same operations. For example, if you have a movie and show endpoints both with the same tag of streaming that have GET operations without operation ids, then having both methods called get will cause a naming clash. Instead, liblab will generate get and get_2 - not developer friendly, and easily fixed by using operation ids.
Response MIME types
When defining response content, you need to specify the MIME type - that is the type of data that is expected to be sent or received. There are many different types that can be received, but some are specific to certain applications due to their data formats.
liblab will handle JSON, text and binary formats such as application/json, text/plain, or application/octet-stream. Any format that ends in +json such as application/ld+json will be handled as JSON with a full response object returned as a type. Other formats that return binary data or strings will come back as the raw response.